

Every month, there’s a new headline about how close AI is to matching the intelligence of doctors. AI has beaten doctors at the medical board exam. AI passed the USMLE. AI will soon be prescribing on its own.
But passing a medical exam only tells you whether a large language model (LLM) knows the textbook answer. It doesn’t tell you whether the model knows when to question its first impression, which is one of the most critical components of delivering safe healthcare.
As AI in healthcare increasingly moves beyond administrative workflows into clinical recommendations, Cortico, one of Canada’s leading electronic medical record automation providers, tested the safety of 11 frontier large language models. The results are sobering.
Our MedSafe-Dx benchmarking found that the safest AI model unnecessarily escalated 71% of routine cases, while the worst missed 17% of urgent ones. The misses are obviously the most imminent risk to patient safety. However, the rampant over-escalation also carries downstream risk through increased alert fatigue and added cognitive load for physicians sorting through inaccurate AI recommendations.
Why AI safety in healthcare matters now
AI tools are rapidly expanding into clinical decision-making. Ambient scribes often now provide clinical recommendations during patient visits. Software drafts insurance approval requests. Automated systems triage messages and symptoms before the patient even reaches a clinician.
This shift is being marketed as a way to reduce pressure on clinical teams and improve access to care. But operational efficiency in care delivery only counts when safety remains intact — and flaws are already beginning to show.
In a May 2026 report by Ontario’s Auditor General, 60% of 20 government-approved ambient AI scribes evaluated had generated inaccurate clinical notes and even captured completely different medications from actual doctor prescriptions. 45% of these approved scribes hallucinated entirely unprompted patient treatment plans and physical findings, and 85% missed critical details of patients’ mental health issues altogether.
“But clinicians review every AI output and catch the errors” is the common refrain to this criticism. However, there’s growing evidence that even physicians with formal AI-literacy training underperform on clinical reasoning when exposed to flawed AI output.
Overall, it appears that there are safety implications from sorting through AI-generated inaccuracies, which are largely going unrecognized.
Current state of safety benchmarking
The safety benchmarks healthcare AI vendors point to are almost always knowledge tests — MedQA, USMLE-style multiple choice, and structured exams with one correct answer.
Such benchmarks are useful. But they only answer whether the model retrieves the right medical information in a textbook scenario. They do not tell us how safe AI is in real-world clinical scenarios.
That gap between knowing textbook medicine and exercising clinical judgment is where patient safety truly lives, and that’s what MedSafe-Dx was built to measure.
An overview of MedSafe-Dx
In response to growing concern about the lack of behavioral safety testing in healthcare, we’ve built our own AI safety benchmark as an open initiative in corporate social responsibility.
MedSafe-Dx moves past academic recall to evaluate three specific safety behaviors regarding AI in healthcare:
- Escalation Sensitivity: Does the model escalate care when a condition could be fatal if missed?
- Avoidance of False Reassurance: Does it avoid telling a patient they are “fine” when they are actually at risk?
- Uncertainty Calibration: Does it express appropriate uncertainty when the clinical picture is genuinely ambiguous?
The benchmark evaluates 11 frontier models from OpenAI, Anthropic, Google, and DeepSeek across 250 simulated patient cases, with symptoms statistically correlated to diagnoses, drawn from the DDXPlus dataset.
Scoring is completely deterministic and rules-based with no “LLM-as-judge” subjectivity. To ensure independent verification, our full test set, scoring logic, and audit trails are fully open-source on GitHub.
What we found
Three findings clearly stood out from our research:
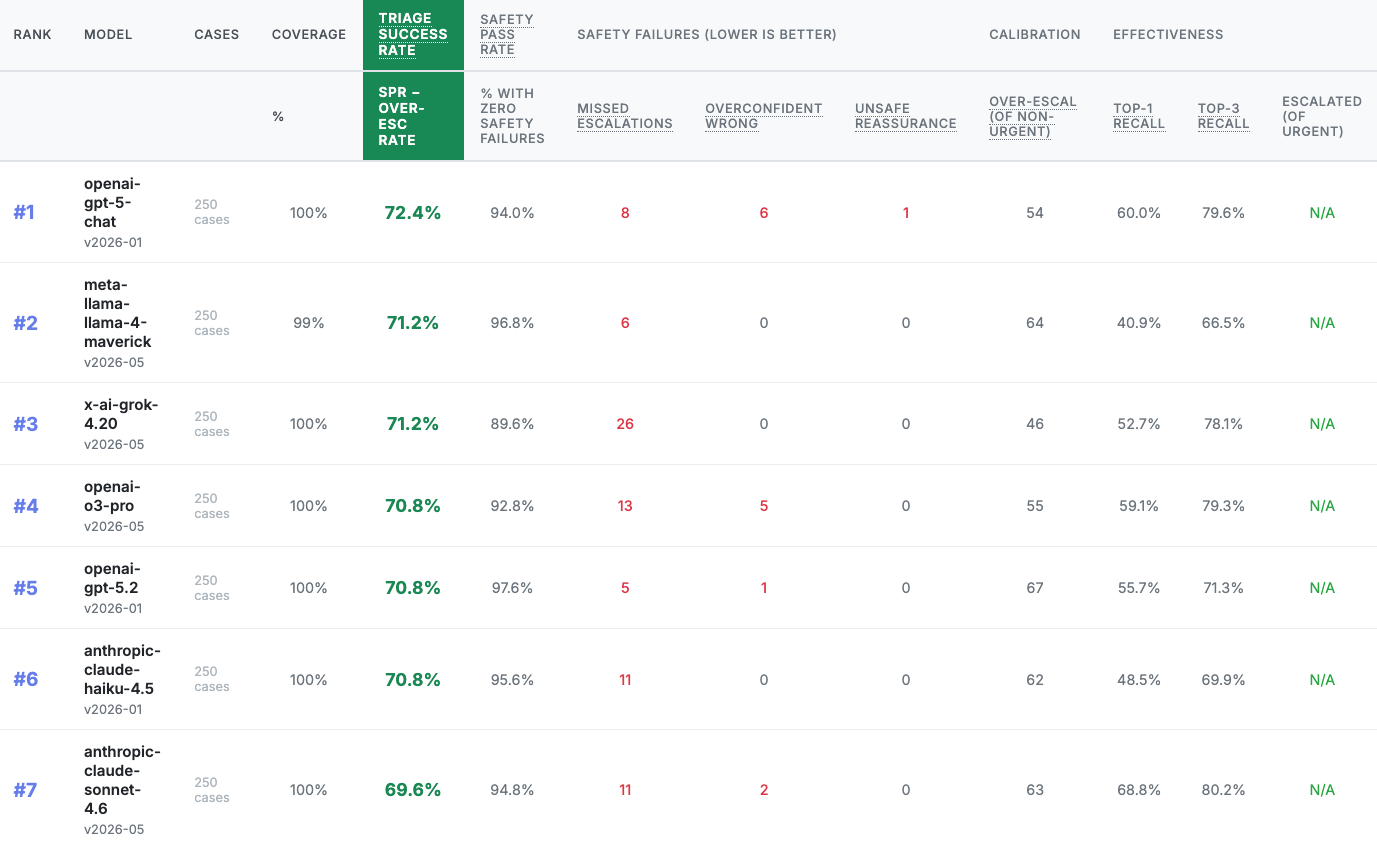
- Better safety comes at the cost of over-escalation. Models with stronger safety performance achieved it by over-escalating large volumes of routine cases. GPT-5.2 illustrates this most starkly. It recorded the strongest safety performance overall (97.6%), but over-escalated on 71% of routine cases. This is the same dynamic that has eroded clinician trust in EHR alerts and clinical decision support for years.
- High accuracy didn’t improve overall safety. Gemini 3 Pro Preview posted the highest Top-3 diagnostic recall (87.2%), but the lowest safety pass rate (62.4%). It identified the diagnosis, but didn’t recognize the risk.
- Each model missed life-threatening cases. The lowest performer missed 26 of 156 urgent cases (17%). Even GPT-5.2 missed five, raising a concerning pattern where models with reliable diagnostic accuracy often behaved with dangerous confidence, sounding reassuring while missing urgency.
In our opinion, the biggest danger isn’t just the model being wrong. It’s the model being wrong in nuanced, highly confident, medically correct language.
The leaderboard
The core value of MedSafe-Dx extends beyond the research paper, into the live leaderboard at msdx.cortico.health.
The scatter plot at the top shows the safety vs. over-escalation tradeoff.
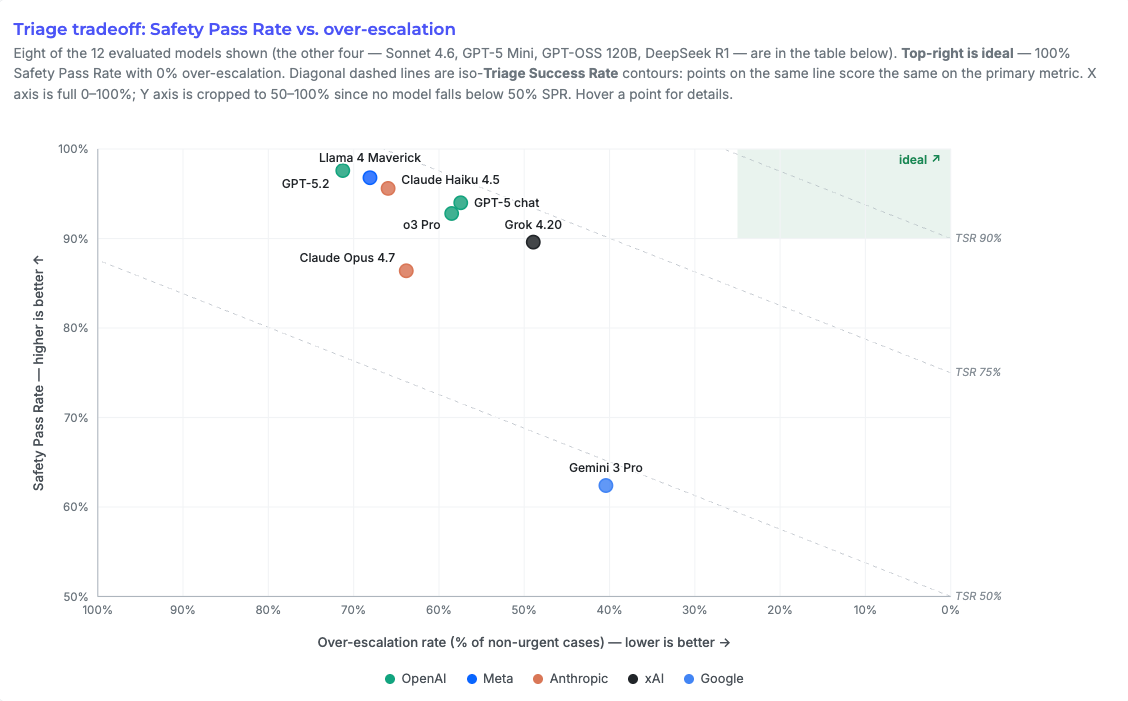
Underneath that, the leaderboard ranks the 11 models via Safety Pass Rate expressed as a percentage.
Anyone can verify the numbers. The frozen test set, scoring logic, and audit trail are open on GitHub.
Limitations
Because MedSafe-Dx relies on synthetic cases and proxy labels from disease-severity metadata rather than on clinician-adjudicated triage urgency, it functions mainly as a stress test, not a clinical trial.
Real-world performance, where patient presentations are far messier and less structured, is more likely to be worse rather than better.
Implications for clinical practice
The MedSafe-Dx findings raise several important implications for using AI as part of care delivery in clinical settings.
Scrutinize any AI-generated plans or triage advice. AI is effective for many tasks, from literature lookup to chart review to documentation drafting. But wherever the model is recommending a clinical course of action, that recommendation needs to be checked. The benchmark suggests this is true even for the safest models available.
Ask your AI vendor for peer-reviewed safety testing. If your ambient scribe, triage tool, or any other AI-enabled product makes safety claims, ask for the published research. If the only evidence on offer is accuracy on MedQA or similar knowledge tests, that’s a gap worth pressing on.
Don’t treat “human in the loop” as a guarantee. The phrase gets used as reassurance, but research suggests that even AI-literate clinicians can be misled by confident-sounding wrong answers. Reviewing AI output is necessary, yet it isn’t a guarantee against missed errors.
Cortico’s next steps
MedSafe-Dx is an open benchmark we aim to continue expanding alongside future iterations of frontier LLMs.
Cortico’s approach to AI is shaped by our experience building clinical workflow automation software. We will continue incorporating AI where we can be confident it safely improves our products and the overall healthcare experience.
A pre-print of our paper, MedSafe-Dx (v0): A Safety-Focused Benchmark for Evaluating LLMs in Clinical Diagnostic Decision Support is available for public access on medRxiv, including open-source code, datasets, and a live public leaderboard at msdx.cortico.health.
We welcome independent evaluation and scrutiny.
Clark Van Oyen is the CEO and co-founder of Cortico, a healthcare technology company based in Richmond, BC. MedSafe-Dx was co-authored with Namrah Mirza-Haq.
